VisoLab is a startup that creates automated self-checkout registers for canteens, where the meals on the tray are recognized on on edge via an iPad, allowing the customer to pay for their meals within seconds without requiring an employee.

Behind the scenes, the system uses a machine learning model, trained to distinguish a vast amount of meals, snacks, drinks, and they way they could be placed on the tray. All the canteen employees have to do every day is to take up to 5 pictures per daily meal, and in two minutes our model is fine-tuned and uploaded to the iPad for on-device inference. The system detects the meals on the tray in not even a second of time, saving a bunch of time and money for canteens and customers!
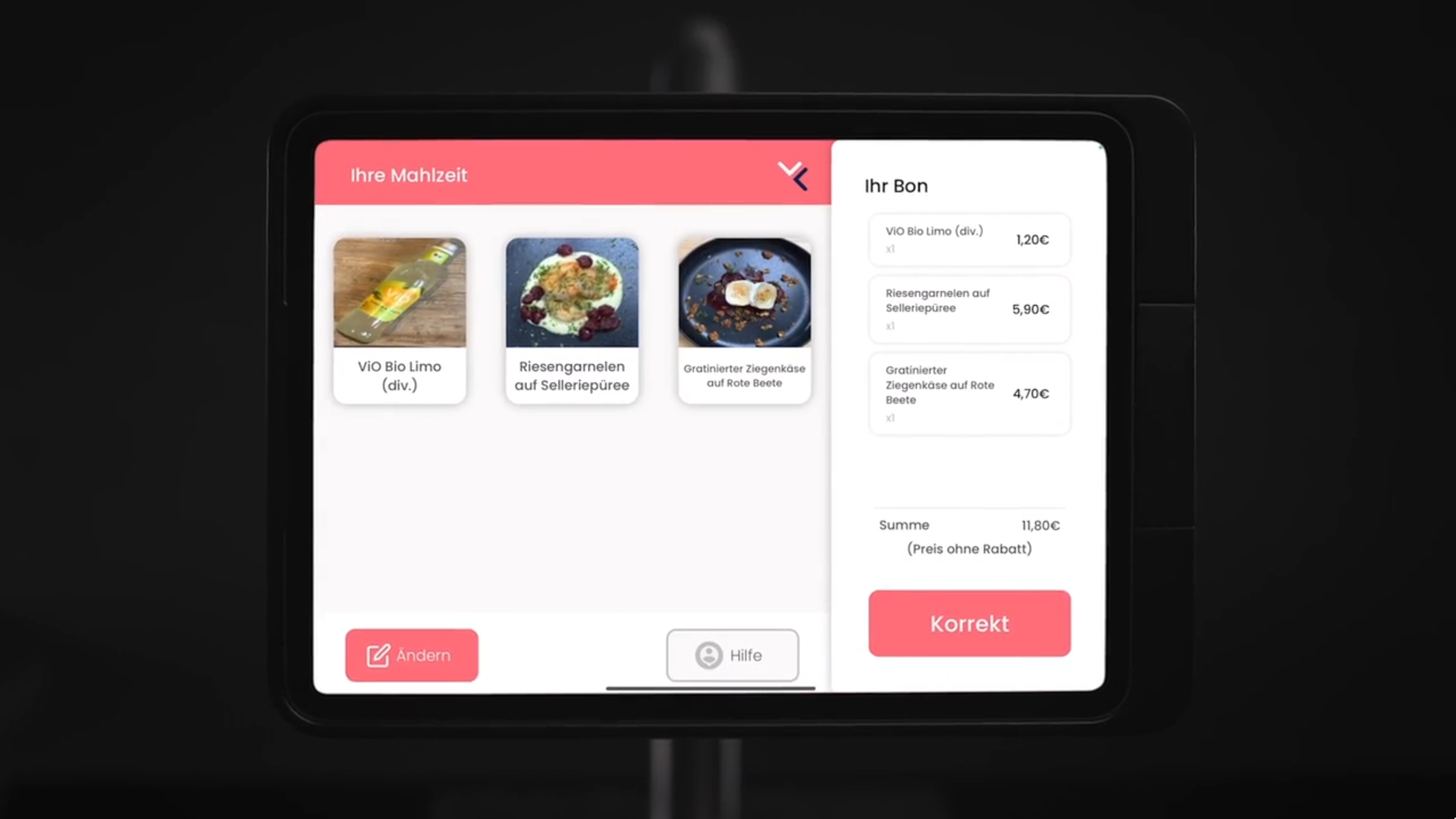
During my 2.5 years at this company, our system evolved from prototype to a highly polished product. When I started, there was only a Raspberry Pi in a 3D-printed case, taking pictures and uploading them to a Google Drive for data collection. To incorporate this data into the model, an employee manually started a Google Colab Notebook and downloaded the result to the Pi. Eventually however, the product became more refined: The frontend became an iPad App, with an onboarding-interface which allows the cooks add the dishes of the day, as well as the checkout-view that the customers get to see.

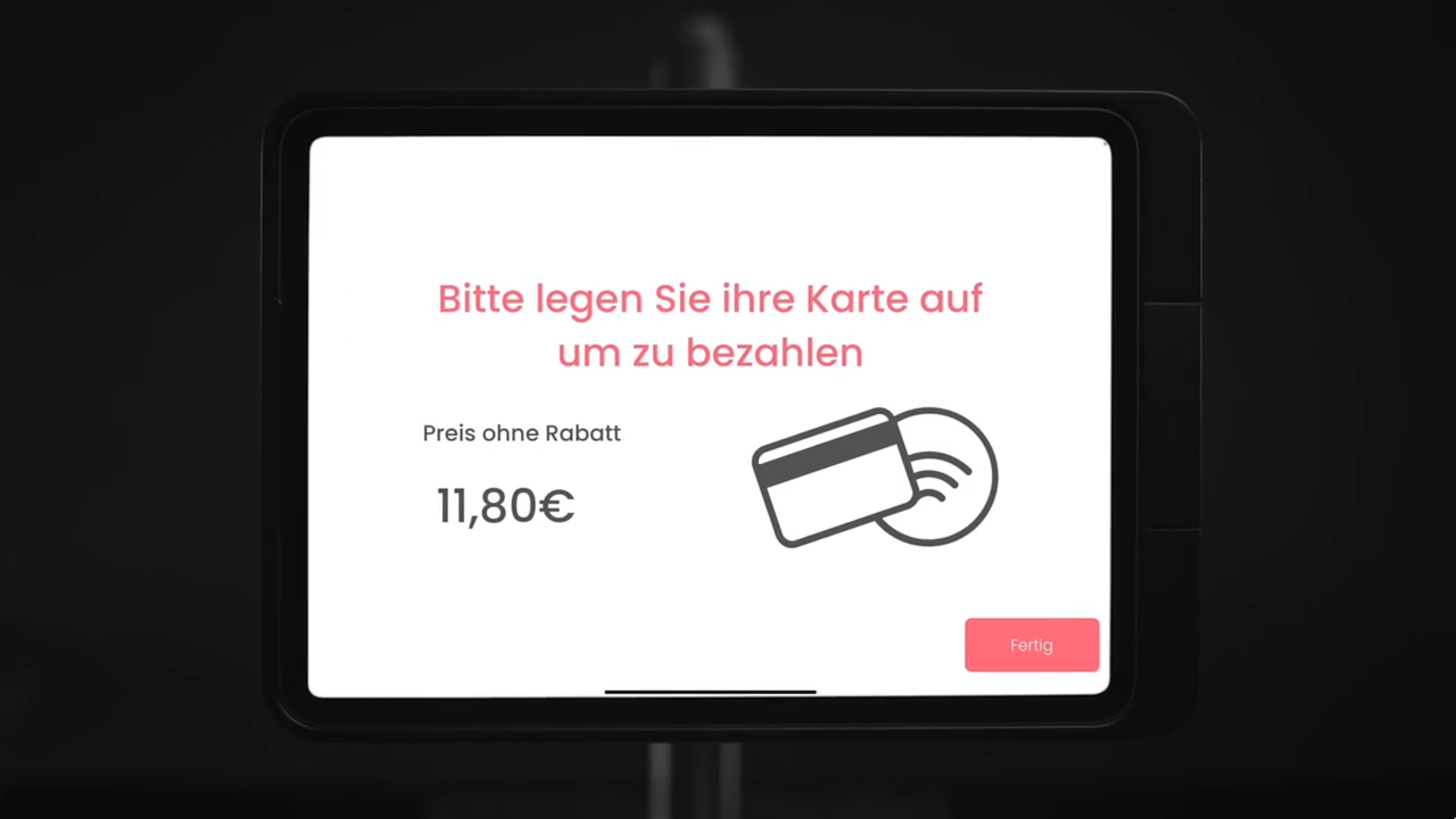
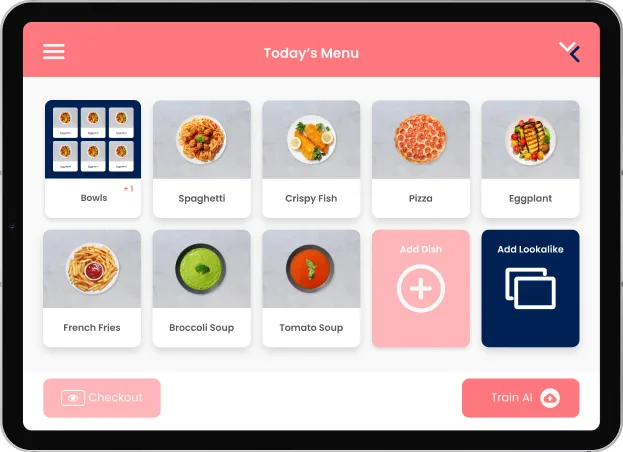
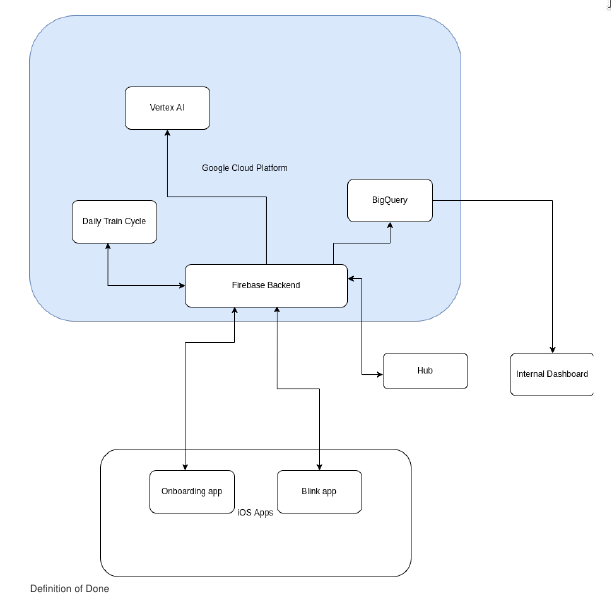
But not only the frontend changed, but the entire software stack was written from scratch. The backend is now hosted on Google Cloud’s Firebase, where Cloud Functions trigger the start of the daily train circle that incorporates new training data in a Kubernetes-Cluster. Every part of our system is adhering to the latest tech standards - we employ microservices that are continually integrated, use mlflow and argo for the model training and bigquery for our data warehouse. All this new infrastructures is set as code thanks to Terraform. Adding a new customer is a matter of seconds, as everything is set up automatically and scales horizontally and vertically. There are multiple APIs to the different cash registers used by our partners, as well as their existing meal planning solutions. Our ML-Model went through many iterations, and is now fully trained on our own data. It takes less than a second for inference, and fully detects a tray with up to 8 items without any intervention in 95% of cases. To achieve that, we created many custom datasets for training and benchmarking.
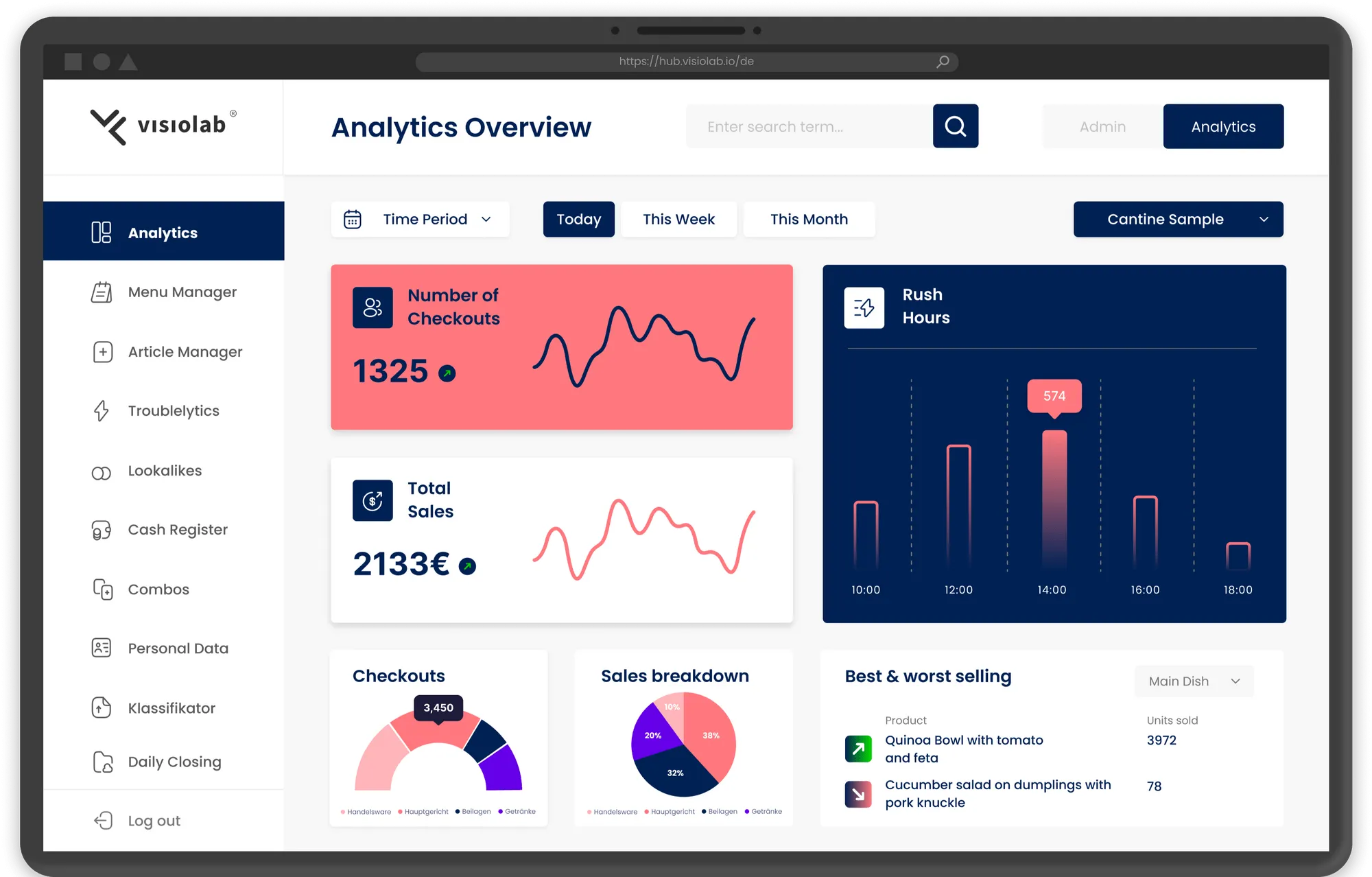
Simple and complex analytics for both our customer service team and the canteen-staff are automatically generated, as well as a suite of alerts, warning of for example bad detection rates. While our team uses aggregate statistics to improve our models, the customers are given detailed information about their best- and worst-selling dishes or rush hours.
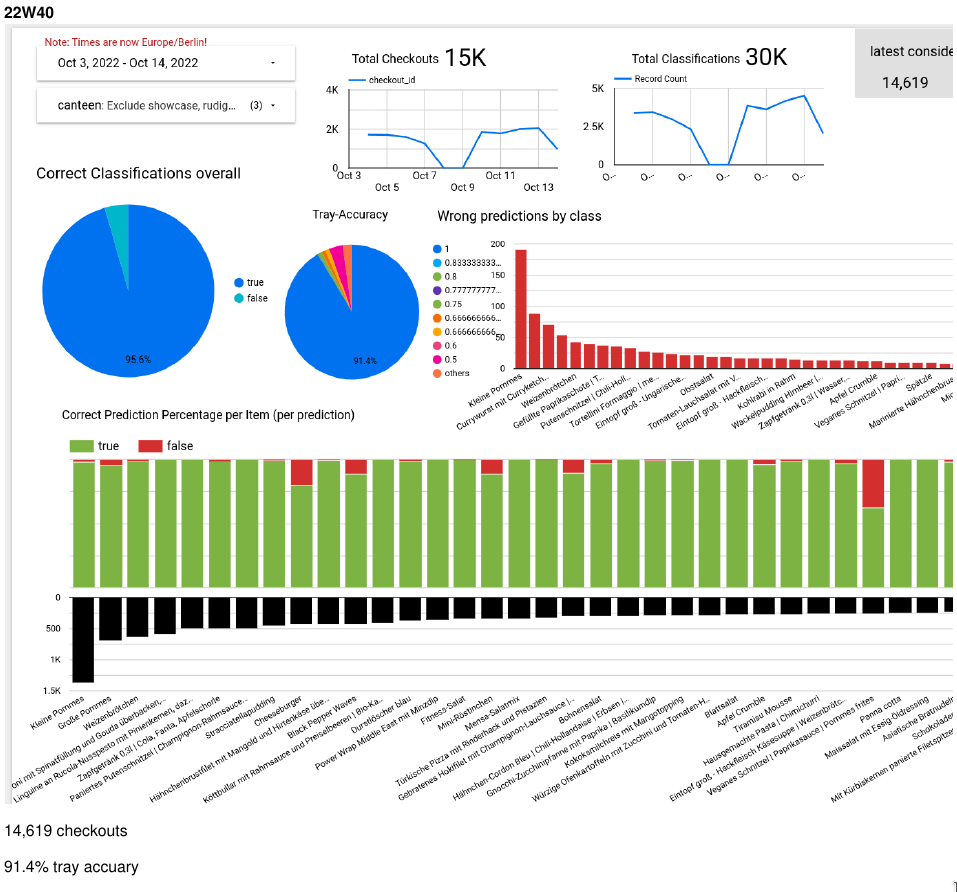
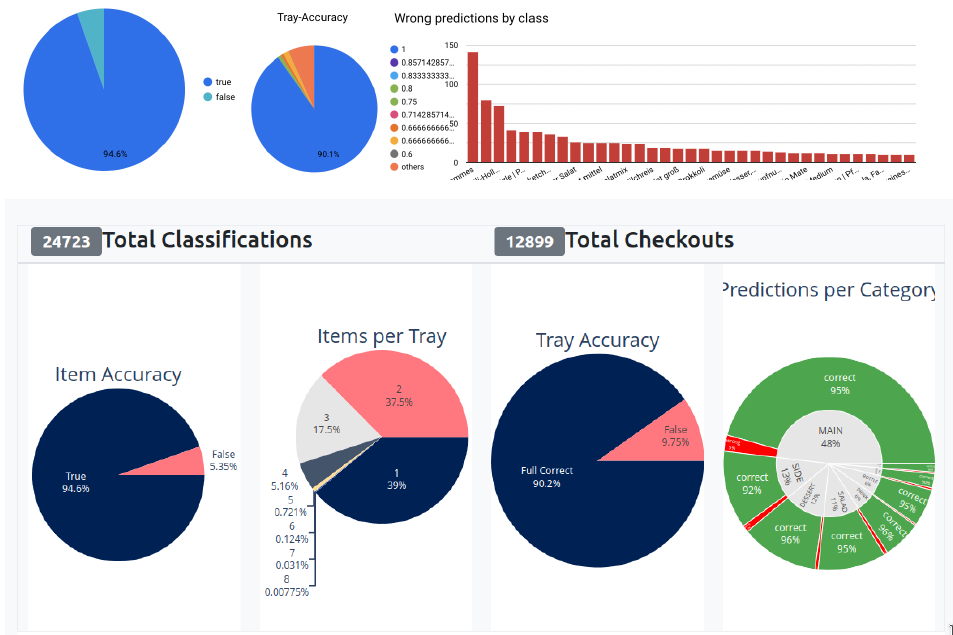
As customers correct wrong classifications, we can continually learn from that, train updated models in the background, and automatically push the new models seemlessly to the iPad. The model itself is a multi-stage-pipeline, first embedding the detected dishes into a latent space (a customized YOLO network which doesn’t need to be updated often), with a custom head that does the final classification. Thanks to our data collection, we have multiple benchmarks datasets as well as our own training pool.
In a young startup such as this, the roles are flexible and what exactly I worked on changed frequently. I was hired as backend developer, but because of my background in machine learning, I was quickly working as a data scientist as well. And because big data can hardly be worked on in Jupyter notebooks, the task soon involved data engineering as well… and as there was no sole person responsible for DevOps, this also soon became one of my responsibilities.
Specifically,
- I created, maintained and added features to our completely new backend, which enables our iOS-App for food recognition and detection. The backend relies on Firebase and is written in TypeScript.
- I worked on the upkeeping and deployment of our infrastructure (daily train circle as gke cluster, mlflow, data warehouse generation, alerting, dashboards, …) which relies on Kubernetes on Google Cloud Services and is fully represented in Code using Terraform.
- I developed ETL-Pipelines using Python and Apache Airflow to process the data and transform it into a data warehouse, and created a Dashboard using Plotly that visualizes all relevant information for our customer service team.
- I co-created our Machine Learning Pipeline, which relies on Argo to train our PyTorch models in a Kubernetes Cluster. Once this was finished, my primary focus shifted to Data Science, where I created and improved our custom models for food classification as well as the benchmarking and training datasets.