VisoLab ist ein Startup, das automatisierte Self-Checkout-Kassen für Kantinen baut: Die Mahlzeiten auf dem Tablett werden on edge über ein iPad erkannt, sodass Gäste innerhalb von Sekunden zahlen können, ohne dass dafür Personal an der Kasse stehen muss.

Hinter den Kulissen nutzt das System ein Machine-Learning-Modell, das darauf trainiert ist, eine große Menge an Mahlzeiten, Snacks und Getränken zu unterscheiden (inklusive der vielen Arten, wie es auf einem Tablett liegen kann). Das Kantinenpersonal muss dafür jeden Tag nur bis zu 5 Bilder pro Tagesgericht machen, und innerhalb von zwei Minuten wird unser Modell fine-tuned und für on-device inference aufs iPad hochgeladen. Das System erkennt die Items auf dem Tablett in unter einer Sekunde und spart so Zeit und Geld - für Kantinen und für die Kundschaft.
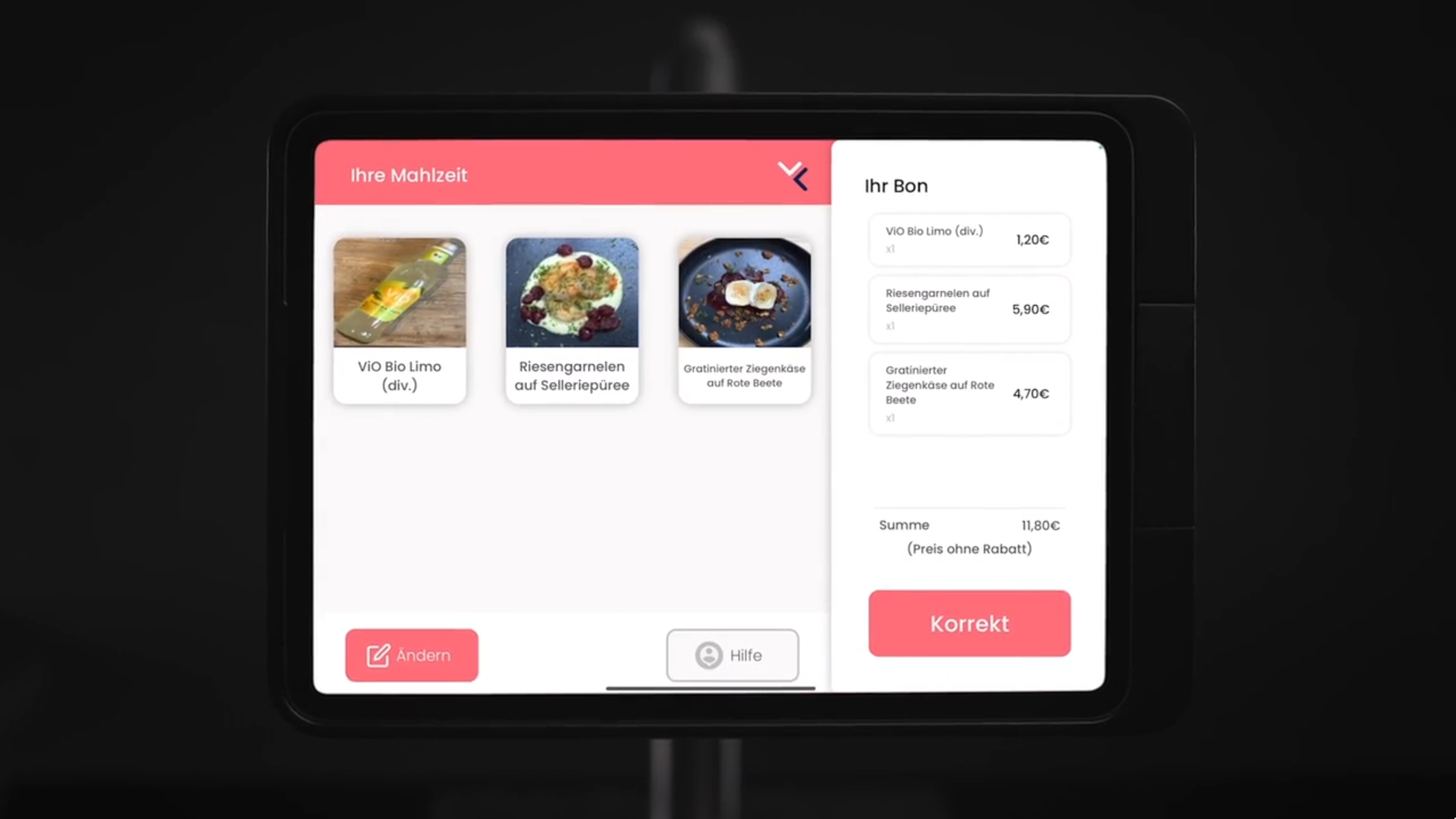
In meinen 2,5 Jahren dort hat sich das System von einem Prototyp zu einem ziemlich polierten Produkt entwickelt. Als ich angefangen habe, gab es im Wesentlichen nur einen Raspberry Pi in einem 3D-gedruckten Case, der Bilder gemacht und zur Datensammlung in ein Google Drive hochgeladen hat. Um diese Daten ins Modell zu bekommen, hat jemand manuell ein Google-Colab-Notebook gestartet und das Ergebnis wieder auf den Pi heruntergeladen. Über die Zeit wurde es dann aber zu einem richig professionellem Produkt: Das Frontend wurde zu einer iPad-App - mit einem Onboarding-Interface, über das das Küchenteam die Gerichte des Tages anlegen kann, sowie einem Checkout-View, den die Gäste sehen.

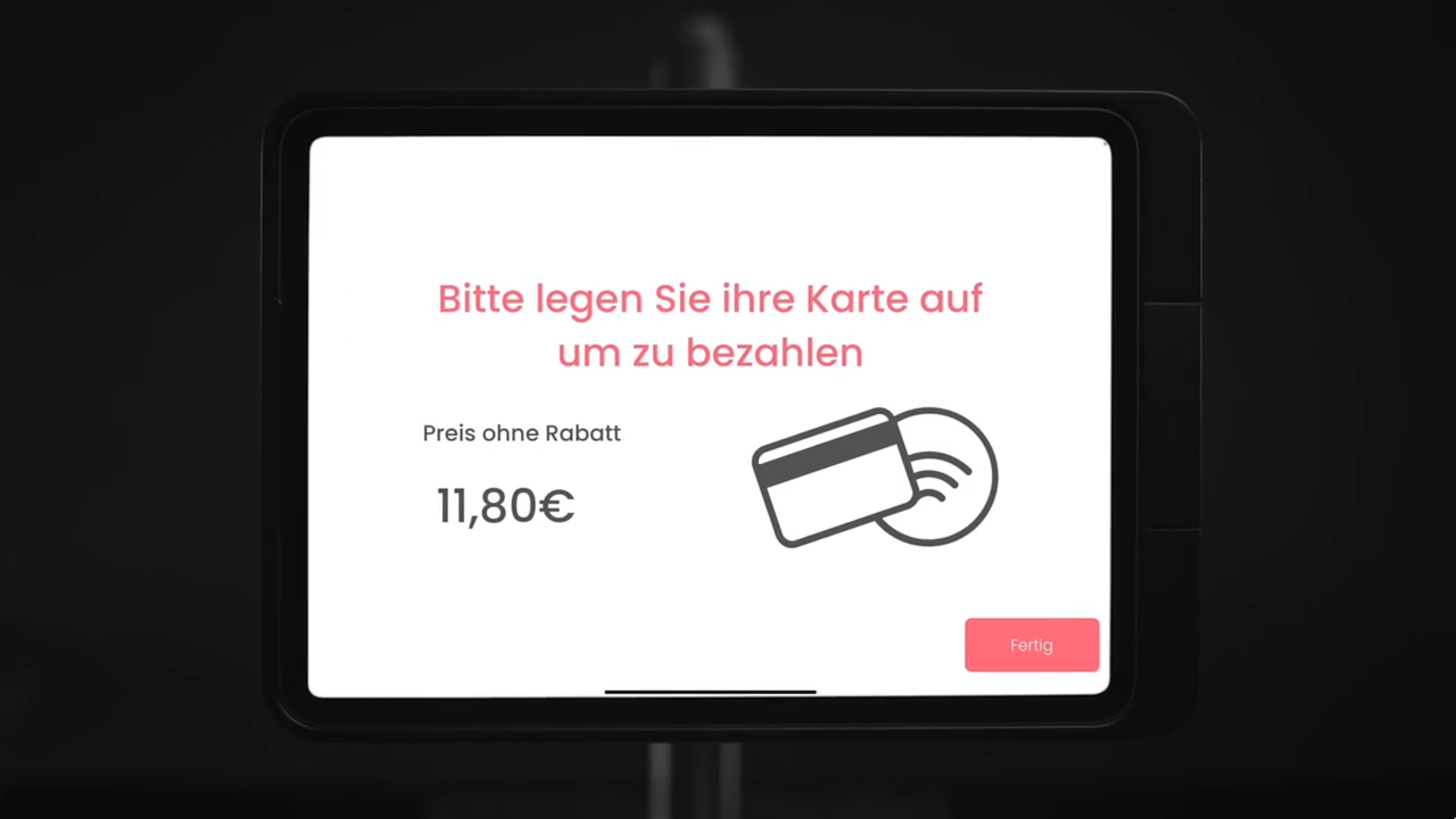
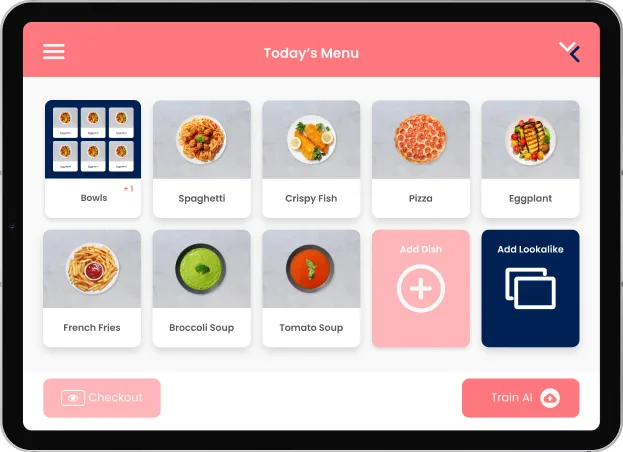
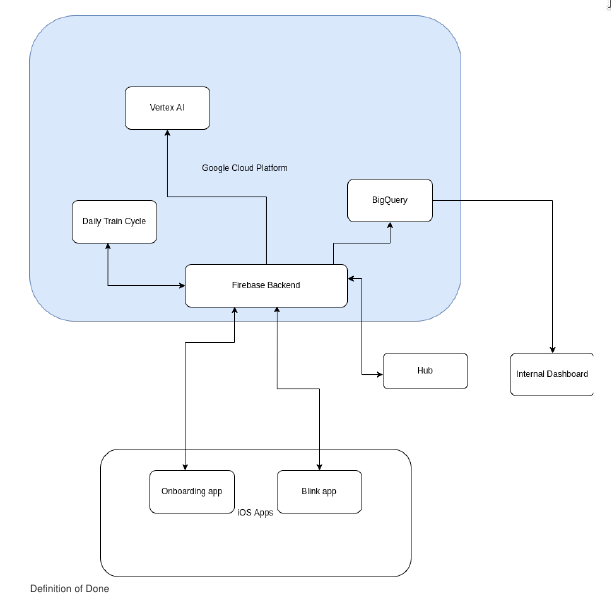
Aber nicht nur das Frontend hat sich geändert - der komplette Software-Stack wurde neu geschrieben. Das Backend läuft inzwischen auf Google Firebase, wo Cloud Functions den Start des täglichen Trainingszyklus triggern, der neue Trainingsdaten in einem Kubernetes-Cluster verarbeitet. Jedes Stück des Systems orientiert sich an aktuellen Tech-Standards: Wir nutzen Microservices, die kontinuierlich integriert werden, mlflow und argo fürs Model-Training, und BigQuery als Data Warehouse. Die ganze Infrastruktur ist dank Terraform als Code abgebildet. Neue Kundschaft anzubinden dauert Sekunden, weil alles automatisch aufgesetzt wird und horizontal wie vertikal skaliert. Es gibt mehrere APIs zu den verschiedenen Kassensystemen, die unsere Partner nutzen, sowie zu deren bestehenden Meal-Planning-Lösungen. Unser ML-Model ist durch viele Iterationen gegangen und wird inzwischen vollständig auf unseren eigenen Daten trainiert. Inference dauert unter einer Sekunde, und ein Tablett mit bis zu 8 Items wird in 95% der Fälle vollständig erkannt - ohne irgendeinen manuellen Eingriff. Dafür haben wir viele Custom-Datasets fürs Training und Benchmarking gebaut.
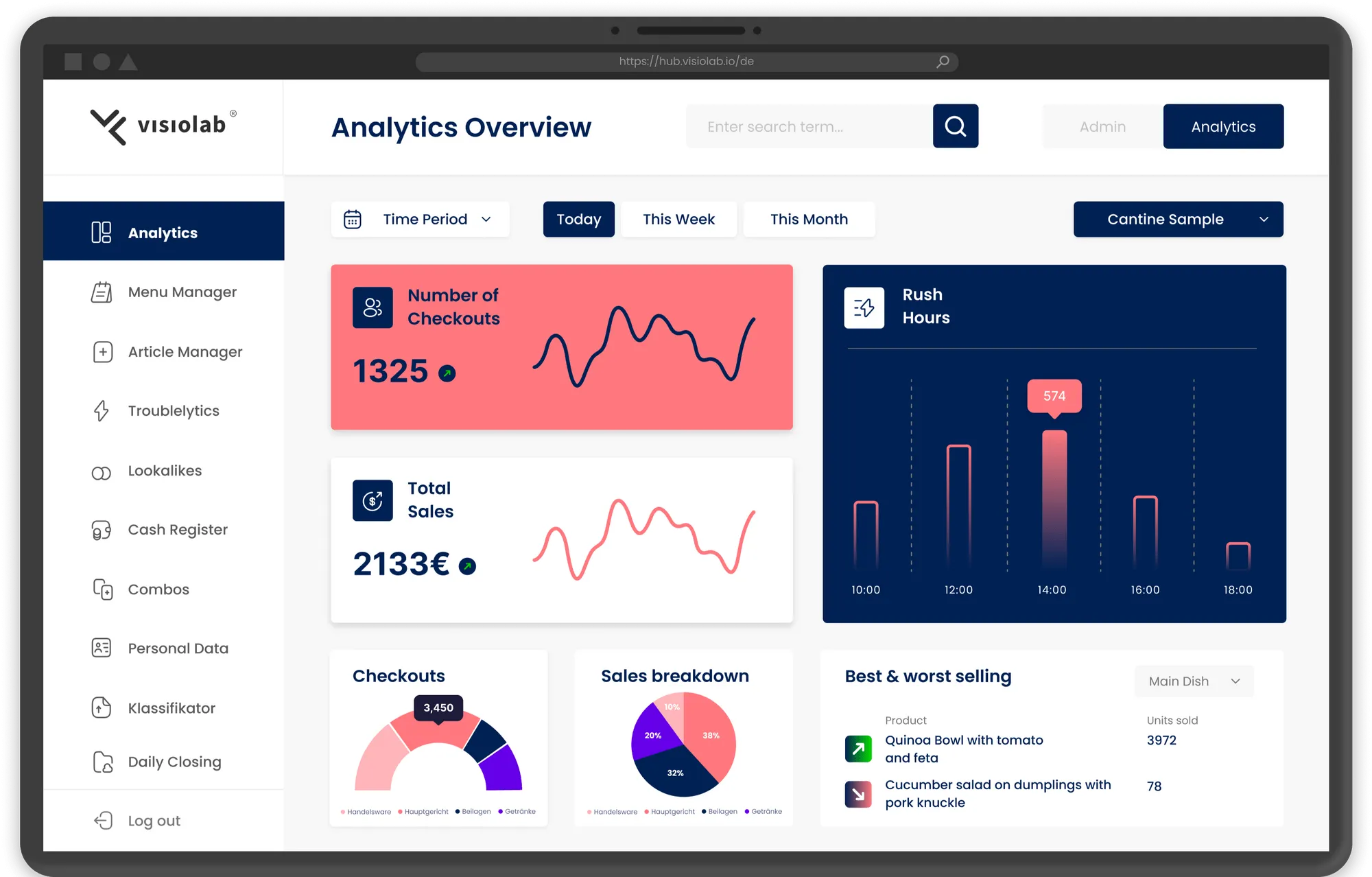
Einfache und komplexe Analytics für unser Customer-Service-Team und für die Kantinen vor Ort werden automatisch generiert, inklusive eines Alerting-Systems, das z.B. vor schlechten Detection-Rates warnt. Während wir im Team mit aggregierten Statistiken die Modelle verbessern, bekommen die Kunden detaillierte Infos zu Best- und Worst-Sellern oder Rush Hours.
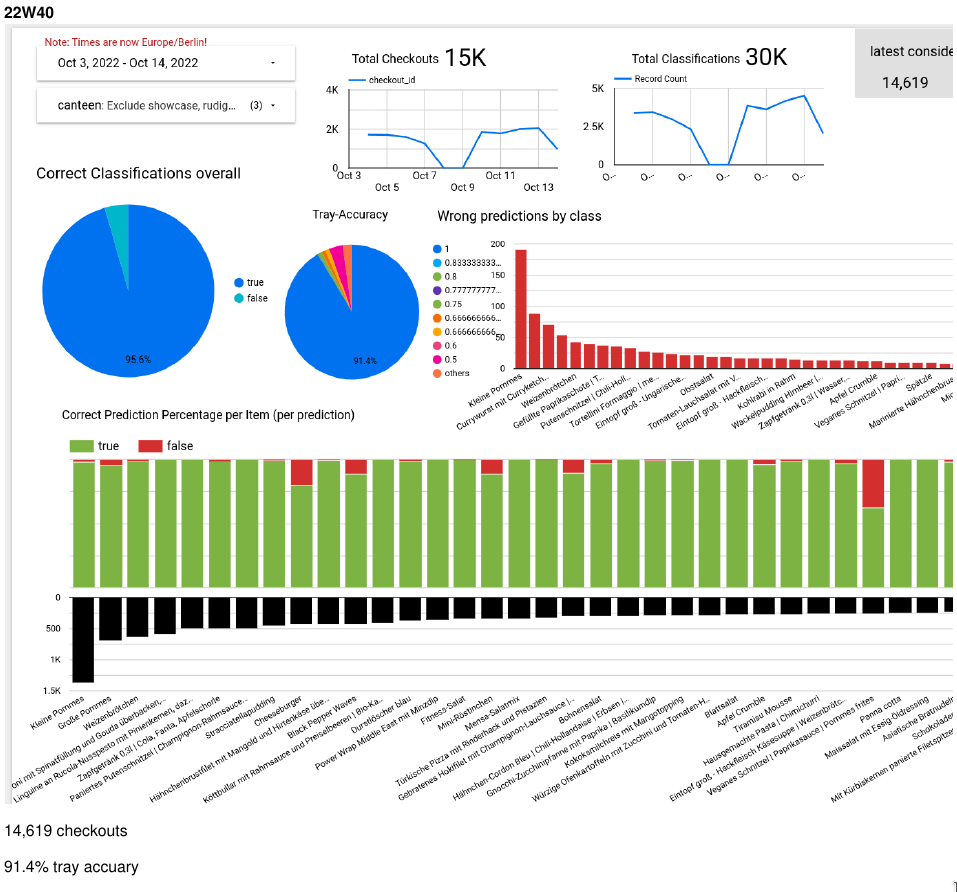
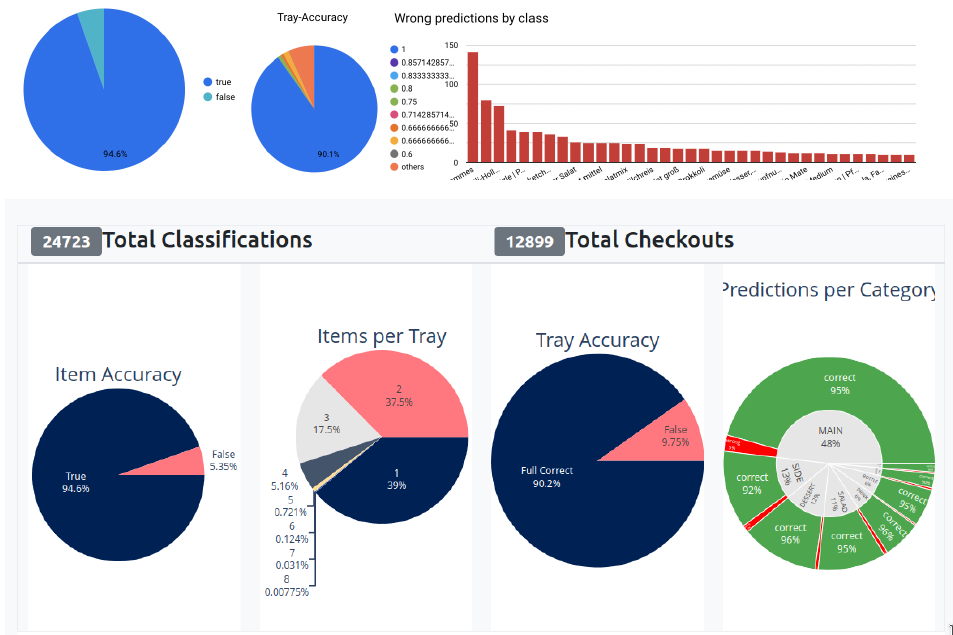
Wenn Kundschaft falsche Klassifikationen korrigiert, können wir daraus kontinuierlich lernen, im Hintergrund neue Modelle trainieren und diese dann automatisch und nahtlos aufs iPad ausrollen. Das Modell selbst ist eine Multi-Stage-Pipeline: Erst werden die detektierten Gerichte in einen Latent Space eingebettet (ein angepasstes YOLO-Netzwerk, das nicht oft aktualisiert werden muss), danach macht ein Custom Head die finale Klassifikation. Durch die Datensammlung haben wir mehrere Benchmark-Datasets sowie unseren eigenen Training Pool.
In einem jungen Startup wie diesem sind Rollen flexibel, und woran ich genau gearbeitet habe, hat sich häufig geändert. Ich wurde als Backend Developer eingestellt, aber durch meinen ML-Background habe ich schnell auch als Data Scientist gearbeitet. Und weil Big Data sich nur begrenzt sinnvoll in Jupyter Notebooks bearbeiten lässt, gehörte bald auch Data Engineering dazu… und weil es niemanden gab, der ausschließlich DevOps gemacht hat, war das dann ebenfalls schnell ein Teil meiner Aufgaben.
Konkret:
- Ich habe unser komplett neues Backend gebaut, maintained und um Features erweitert, das die iOS-App für Food Recognition und Detection ermöglicht. Das Backend basiert auf Firebase und ist in TypeScript geschrieben.
- Ich habe unsere Infrastruktur betrieben und deployed (täglicher Trainingszyklus als GKE-Cluster, mlflow, Data-Warehouse-Generation, Alerting, Dashboards, …), die auf Kubernetes auf Google Cloud Services läuft und vollständig als Code via Terraform abgebildet ist.
- Ich habe ETL-Pipelines mit Python und Apache Airflow entwickelt, um Daten zu verarbeiten und in ein Data Warehouse zu transformieren, und ein Plotly-Dashboard gebaut, das alle relevanten Infos für unser Customer-Service-Team visualisiert.
- Ich habe an unserer Machine-Learning-Pipeline mitgebaut, die Argo nutzt, um unsere PyTorch-Modelle in einem Kubernetes-Cluster zu trainieren. Danach hat sich mein Fokus stärker Richtung Data Science verschoben: Custom Models für Food Classification sowie Benchmarking- und Trainings-Datasets bauen und verbessern.